
阅读本文大概需要 17 分钟。
最近公司招聘海外后端研发,所以整理一份技术栈的资料给他们,但是想来这份整理也适用于所有后端研发,所以去掉了敏感内容,把它呈现于此。
本文重在概述,毕竟篇幅有限,欢迎「关注」,后续可能把单点拓展成文,详细地一一阐述,另外笔者见识有限,毕竟也没有可能在所有大厂工作过,所以如果有疏漏可以在留言处赐教。
目录:
Thrift 服务发现 Consul 微服务框架
Mysql Mycat DRC
Redis Redis集群化方案
RocketMQ Kafka
后端开发概述
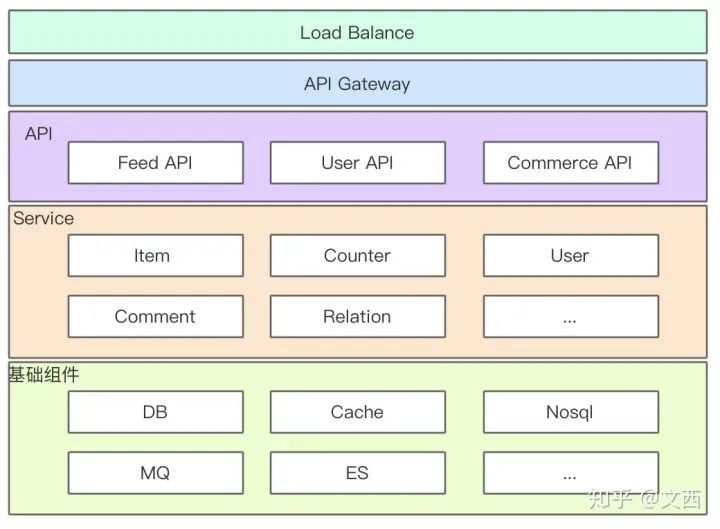

负载均衡 – Load Balance(LB)
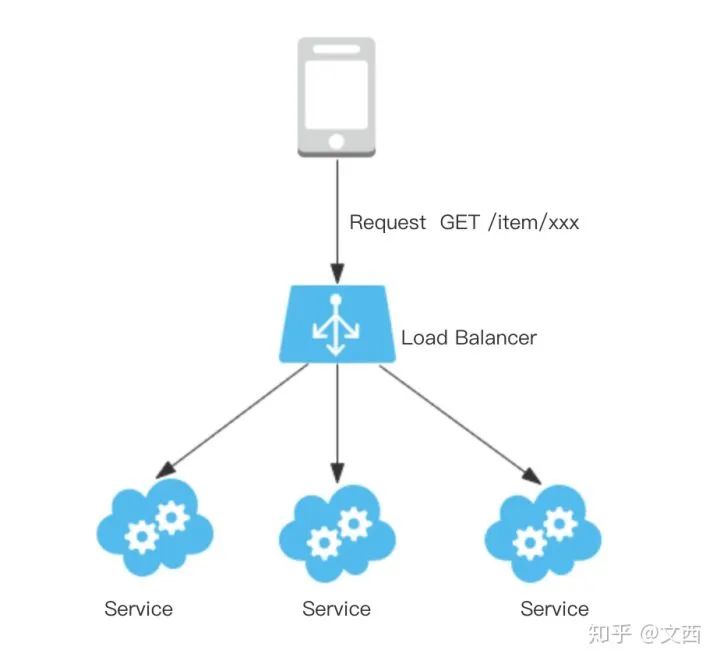
upstream user_api {
server 10.0.6.108:7080;
server 10.0.0.85:8980;
}
#配置转发到 user_api upstream
location /user {
proxy_pass http://user_api;
}
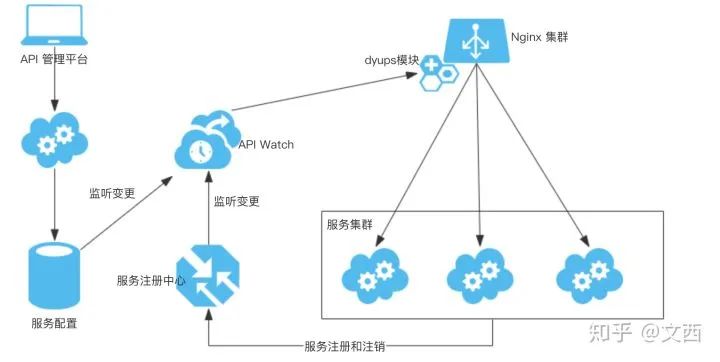
微服务生态
服务可以单独编写、发布、测试、部署,相比于所有功能集中于一体的单体服务,可维护性更强 服务彼此之间依赖服务通信的方式松耦合 按照业务领域来组织服务,每个团队维护各自的服务

Thrift
服务发现
Consul
数据库(Database)
Mysql
Mycat
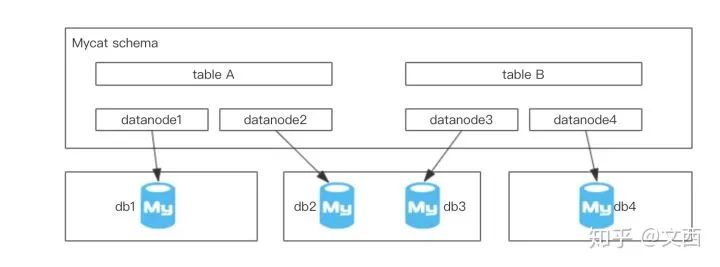
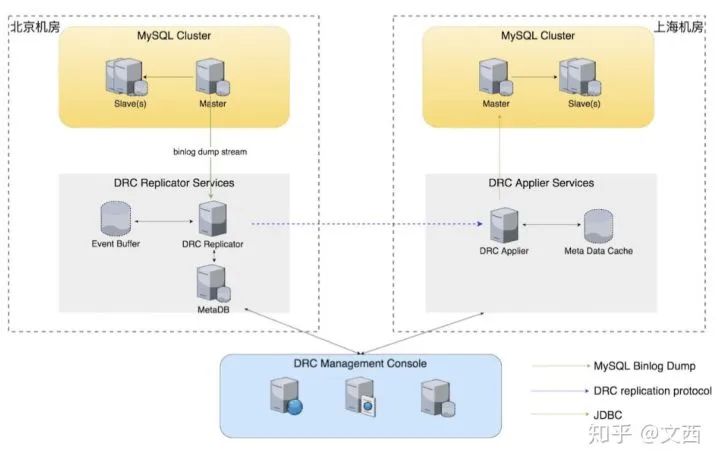
DRC
缓存(Cache)
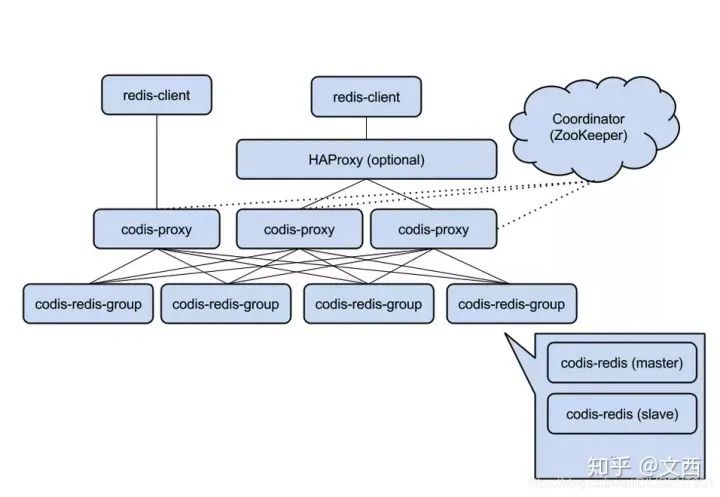
Redis
Redis 集群方案
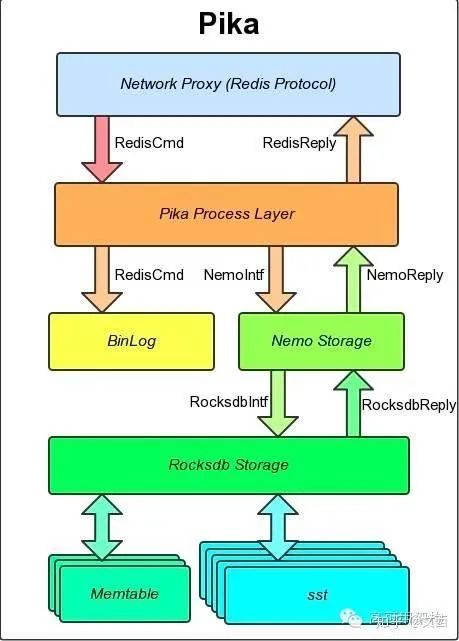
KV-DB
消息队列(MQ)
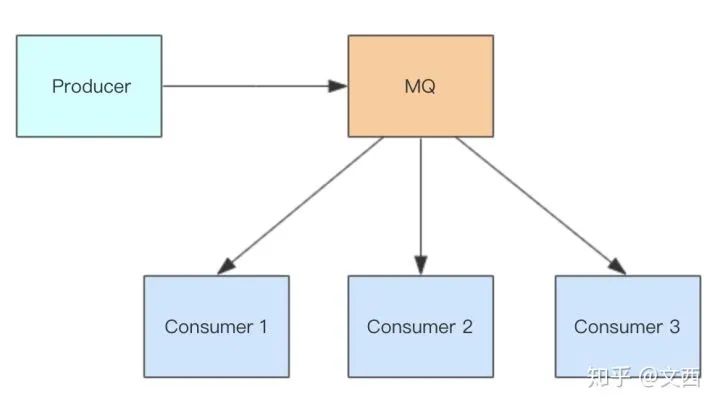
RocketMQ
Kafka
对象存储
Elastic Search
推荐阅读:

微信扫描二维码,关注我的公众号
朕已阅 
文章收集整理于网络,请勿商用,仅供个人学习使用,如有侵权,请联系作者删除,如若转载,请注明出处:http://www.cxyroad.com/1576.html
